
Image Intelligence Analysis Based on Big Data to Search Vehicles
The car search technology is based on computer vision, image processing, and image recognition technologies. It includes four major steps: image preprocessing, image feature extraction, image feature indexing, and image feature matching.
Image preprocessing
The images in complex backgrounds usually have a variety of noises, low resolution, and uneven illumination. In order to make the images have a unified attribute, the images need to be pre-processed to achieve the purpose of position calibration and gray-scale normalization. Firstly, the image background is differentiated and filtered to denoise, and then the reduction and amplification transformation is performed to obtain a fixed-size image sample, so that the subsequent algorithm can perform uniform processing and identification for a fixed sample; then, the image is gray-scaled and passes the median value. Filtering and morphological methods enhance the image so that the main textures of the vehicle features (such as license plate numbers, body colors, vehicle local features, etc.) are clearly discernible, the interference texture blurring is weakened, and the image is optimized for texture-based vehicle feature positioning; finally, the histogram is used. The equalization technique allows the image to have a uniform mean and variance, resulting in a standard image.
Image feature extraction
Compared with other popular detection methods (Harris detectors), the advantage of SIFT feature vectors is that they not only have good invariance to scaling, translation, rotation, and brightness changes, but also have problems with partial occlusion and image background noise. Good retrieval performance; and its rich information and uniqueness, suitable for a large number of feature databases; in addition, a large number of SIFT feature vectors can be obtained through a few goals. Therefore, SIFT-based algorithm is used to complete the feature vector representation of the image in the database. The feature vector extracted by this algorithm has 128-dimension to avoid the occurrence of dimensional disaster while reducing the computational complexity when matching the feature vectors of the image. The PCA-SIFT which can maintain the good characteristics of the SIFT operator and effectively reduce the dimension of the feature vector is adopted. The algorithm performs image local feature extraction. Firstly, the SIFT features are extracted from the image uniformly, and then the Principal Component Analysis (PCA) is performed. Then the image is transformed according to the eigenvector matrix, and several measured variables are converted into a few irrelevant synthetic indicators. The specific steps for image feature extraction are:
1 Enter the original vehicle gallery
The vehicle area is defined as a rectangular area on the front of the vehicle, with the upper edge to the top of the cab window, the lower edge to the bottom of the license plate, the left edge to the left edge of the vehicle cab window window, and the right edge to the right edge of the cab window.
2 Extract the SIFT feature set from the picture library
Extracting SIFT feature points first requires building a Gaussian pyramid of the image. Its purpose is to divide the image into blocks to make it appear as a hierarchical pyramid structure. Then, the characteristics of each sub-block are separately counted. Finally, the characteristics of all the sub-blocks are stitched together to form a complete feature.
3 Using the PCA Algorithm to Reduce Dimensions
First, calculate the average value for the existing data set P = {P1, PZ, ..., Pn} and subtract the mean value from the original data to obtain Pi' = Pi - M. Then calculate the covariance matrix. Then, the eigenvalues ​​E1, E2,..., Em and eigenvectors EV1, EV2,..., EVm of the covariance matrix are calculated. Finally, the eigenvalues ​​are arranged in ascending order to obtain E1′, E2′,..., Em′. The corresponding feature vectors are EV1′, EV2′,..., EVm′. The eigenvectors represent the distribution direction of the original data. The larger the eigenvalues ​​corresponding to the eigenvectors, the more important the eigenvectors are, namely the main element, also called the principal component.
After the above steps are completed, the first 32 are selected according to the size of the feature value, and the original data can be reduced from the original 128-dimensional to the new 32-dimensional, and the dimensionality-reducing processing operations for the original data are completed.
4 Discretization of SIFT Feature Sets Using K-means Clustering
A large number of SIFT feature sets can be extracted from the gallery and can be discretized using K-means clustering. The poly mark is the image index value. K-means clustering divides each SIFT feature into its nearest cluster by iterative method. The final SIFT feature set is divided into K discrete clusters, and SIFT features of the same cluster are considered to be the same. You can use class numbers to represent SIFT features, discrete SIFT features. The single link method is adopted for the distance between classes, and the calculation formula for any two clusters ci, cj and single connection method is:
In the preferred example herein, a K value of 100,000 is taken.
5 Generate Neighborhood Features
In order to compensate for the lack of SIFT features that lack the feature-relative positional relationship, the discretized SIFT is further transformed into a neighborhood feature. Assuming that the number of SIFT clusters is K, and the neighborhood of N*N is selected, the neighborhood features can be represented as an integer sequence, and the values ​​of their elements do not exceed K*N*N. Given a SIFT feature point, define an N*N neighborhood centered on it. Generate a matrix according to the following rules: Within the same sub-region, the same discrete SIFT feature occurs more than once once; If the k-th discrete SIFT feature appears in the nth region, the k-th value of the n-th row of the matrix is ​​set. It is 1, otherwise it is set to 0. The final sequence of integers is generated according to the following steps: The initial sequence is empty, from left to right, scan code matrix from top to bottom, if the kth value of the nth row is 1, then add an integer to the sequence, the value is ( N-1) * K + k, ignoring the value of the 0 element, which results in an integer sequence, this sequence is the neighborhood feature. FIG. 1 is a schematic diagram of generation of neighborhood features when K=10 and N=3. In the preferred example herein, K takes 100,000, and N takes 3.
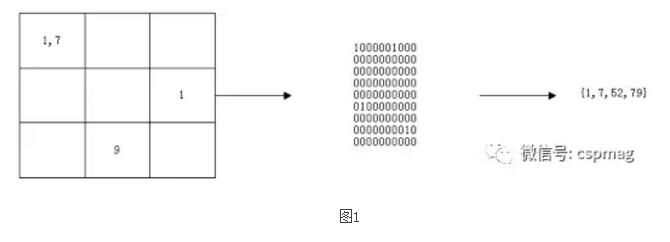
figure 1
Create an image feature index
The inverted index technology used in image retrieval originates from the field of document retrieval and is used for indexing and matching large-scale document data. Inverted indexing is widely used in similarity search. In large-scale image data sets, the low-level feature vectors of the image are quantified as visual words by trained eigenvector codebooks, and each visual word obtained corresponds to an index item in an inverted index. Fast retrieval in image retrieval.
Image feature matching
Given a feature to be searched, after quantization, the index item Wi corresponding to the feature to be searched in the inverted index is determined. Thus, a list of related index features corresponding to the index item Wi is used as a candidate matching result. The definition of the matching function between the two image feature vectors x and y is as follows:
Fq(x,y)=δq(x),q(y)
Where q(.) is a quantization function, which maps the feature vector to the nearest cluster center in the codebook, ie, the codeword.
After the above process, the similarity calculation problem between the user-entered template image and all the images in the image library is transformed into the problem of matching between these local features consisting of binary strings. The similarity measure of the binary strings in this paper uses the Hamming distance. High computational efficiency. Finally, the corresponding image in the image library can be output from high to low according to the matching similarity.
Gasoline Pressure Washer,Gasoline High Pressure Washer,Industrial Gasoline Pressure Washer,Industrial Gasoline High Pressure Washer
Taizhou Chendi Electromechanical Co., Ltd. , https://www.chinachendi.com